
Dependency Injection
Organization is essential to scale. Compare the two images of cabling a data center:


Obviously, the top image appears much more organized. I don’t think it is accidental that the better organized approach is visible in the larger data center. In order to scale, you need organization. If you have a small number of servers, a haphazard cabling scheme is less likely to impact your ability to trace and fix network problems. Such an approach would not work for a million-node data center.
The same is true of code. Without many of the visual cues we use to navigate the real world, tracking code can be very difficult. Thus, code can degenerate into chaos as fast or faster than physical devices. Indeed, the long standing name for poorly organized code is “Spaghetti Code” which is an analogy to the same kind of linear mess we can visualize with the network cables.
Dependency injection provides a tool to help minimize the chaos. Instead of wires run across the data center direct from one machine to another, the well organized scheme routes them to intermediate switches and routers in a standardized way. Just so, dependency injection provides an mediator between components, removing the need for one component to know the approach used to create the specific instance.
The guiding rule is that dependency injection separates object use from object construction.
Table of contents
Constructor Dependency Injection
Of the three forms of Dependency Injection that Martin Fowler enumerates, only the constructor form enforces that an object always meets its invariants. The idea is that, once the constructor returns the object should be valid. Whenever I start working with a new language, or return to an old language, I try to figure out how best to do dependency injection using constructors.
I have a second design criteria, which is that I should continue to program exclusively in that language. Using a marshaling language like XML or YAML as a way to describe how objects interact breaks a lot of the development flow, especially when working with a debugger. Thus, I want to be able to describe my object relationships inside the programming language.
With these two goals in mind, I started looking in to dependency injection in Go.
Approach
There is a common underlying form to the way I approach dependency injection. The two distinct stages are:
- For a given Type, use the languages type management system to register a factory method that describes how to construct it.
- For a given type, use the languages type management system to request an instance that implements that type via a lazy load proxy that calls the factory method.
- When a factory method requires additional objects to fulfill dependencies it uses the same lazy load proxies to fulfill those dependencies.
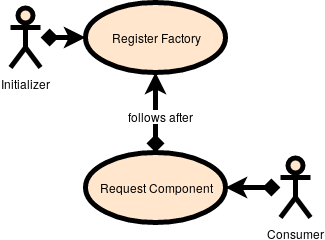
This approach works well with a language that provides the ability to program using the Type system. C++ Supports this via template meta-programming. A comparable version can be done in Java using Generics.
Go provides minimal reflection capabilities. The above design goals pushes them to their limits, and perhaps a bit beyond.
Golang Reflection
The API to request the type of an object in Go is
reflect.TypeOf(object) |
IN order to avoid creating an object just to get its type information, go allows the following workaround:
reflect.TypeOf((*rest.RESTClient)(nil) |
This will return an object of reflect.Type.
Proof of Concept
Here is a very minimal Dependency Injection framework. A factory is defined with a function like this:
func createRestClient(cc dependencies.ComponentCache, _ string) (interface{}, error) { return kubecli.GetRESTClient() //returns two values: *rest.RESTClient, error } |
And registered with the ComponentCache via a call that references the type:
CC = dependencies.NewComponentCache() CC.Register(reflect.TypeOf((*rest.RESTClient)(nil)), createRestClient) |
Code that needs to Get a rest client out of the component cache uses the same form of reflection as the registration function:
func GetRestClient(cc dependencies.ComponentCache) *rest.RESTClient { t, ok := cc.Fetch(reflect.TypeOf((*rest.RESTClient)(nil))).(*rest.RESTClient) if !ok { panic(t) } return t } |
Here is a rough way that the classes work together:
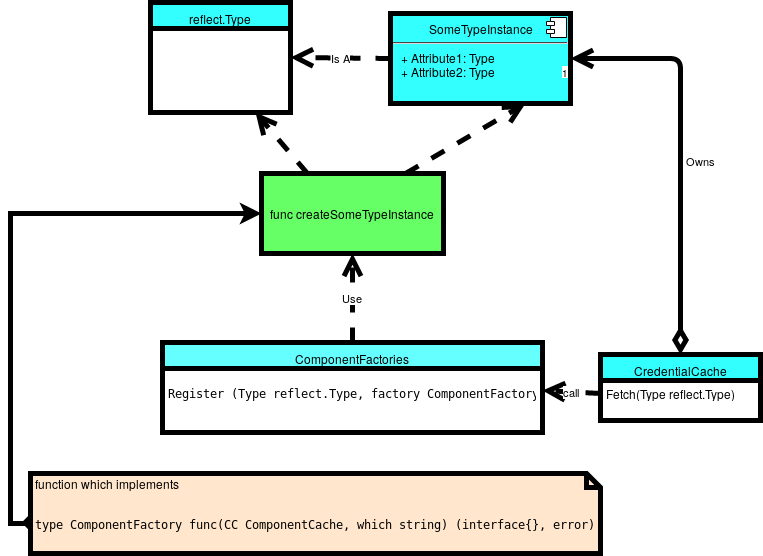
Implementation
The rest of the code for implementing this framework is included below.
package dependencies import "reflect" type ComponentFactory func(CC ComponentCache, which string) (interface{}, error) type ComponentKey struct { Type reflect.Type which string } type ComponentCache struct { components map[ComponentKey]interface{} factories map[ComponentKey]ComponentFactory } func NewComponentCache() ComponentCache { cc := ComponentCache{ components: make(map[ComponentKey]interface{}), factories: make(map[ComponentKey]ComponentFactory), } return cc } func (cc ComponentCache) Register(Type reflect.Type, factory ComponentFactory) { var which string which = "" key := ComponentKey{Type, which} cc.factories[key] = factory } func (cc ComponentCache) RegisterFactory(Type reflect.Type, which string, factory ComponentFactory) { key := ComponentKey{Type, which} cc.factories[key] = factory } func (cc ComponentCache) FetchComponent(Type reflect.Type, which string) interface{} { key := ComponentKey{Type, which} var err error if component, ok := cc.components[key]; ok { return component } else if factory, ok := cc.factories[key]; ok { //IDEALLY locked on a per key basis. component, err = factory(cc, which) if err != nil { panic(err) } cc.components[key] = component return component } else { panic(component) } } func (cc ComponentCache) Fetch(Type reflect.Type) interface{} { return cc.FetchComponent(Type, "") } func (cc ComponentCache) Clear() { //Note. I originally tried to create a new map using // cc.components = make(map[ComponentKey]interface{}) // but it left the old values in place. Thus, the brute force method below. for k := range cc.components { delete(cc.components, k) } } |
This is a bit simplistic, as it does not support many of the use cases that we want for Dependency Injection, but implementing those do not require further investigation into the language.
interfaces
Unlike structures, Go, does not expose the type information of interfaces. Thus, the technique of
reflect.TypeOf((* SomeInterface)(nil))
Will return nil, not the type of the interface. While I think this is a bug in the implementation of the language, it is a reality today, and requires a workaround. Thus far, I have been wrapping interface types with a structure. An example from my current work:
type TemplateServiceStruct struct { services.TemplateService } func createTemplateService(cc dependencies.ComponentCache, _ string) (interface{}, error) { ts, err := services.NewTemplateService(launcherImage, migratorImage) return &TemplateServiceStruct{ ts, }, err } |
And the corresponding accessor:
func GetTemplateService(cc dependencies.ComponentCache) *TemplateServiceStruct { return CC.Fetch(reflect.TypeOf((*TemplateServiceStruct)(nil))).(*TemplateServiceStruct) } |
Which is then further unwrapped in the calling code:
var templateService services.TemplateService templateService = GetTemplateService(CC).TemplateService |
I hope to find a better way to handle interfaces in the future.
Follow on work
Code generation
This approach requires a lot of boilerplate code. This code could be easily generated using a go generate step. A template version would look something like this.
func Get{{ Tname }}(cc dependencies.ComponentCache) *{{ T }} { t, ok := cc.Fetch(reflect.TypeOf((*{{ T }} )(nil))).(*{{ T }}) if !ok { panic(t) } return t } func create{{ Tname }}(cc dependencies.ComponentCache, _ string) (interface{}, error) { {{ Tbody }} } |
Separate repository
I’ve started working on this code in the context of Kubevirt. It should be pulled out into its own repository.
Split cache from factory
The factories should not be directly linked to the cache . One set of factories should be capable of composing multiple sets of components. The clear method should be replaced by dropping the cache completely and creating a whole new set of components.
In this implementation, a factory can be registered over a previous registration of that factory. This is usually an error, but makes replacing factories for unit tests possible. A better solution is to split the factory registration into stages, so and factories required for unit tests are mutually exclusive with factories that are required for live deployment. In this scheme, re-registering a component would raise a panic.
Pre-activate components
A cache should allow for activating all components in order to ensure that none of them would throw an exception upon construction. This is essential to avoid panics that happen long after an application is run triggered via uncommon code paths.
Multiple level caches
Caches and factories should be able to work at multiple levels. For example, a web framework might specify request, session, and global components. If a factory is defined at the global level, the user should still be able to access it from the request level. The resolution and creation logic is roughly:
func (cc ComponentCache) FetchComponent(Type reflect.Type, which string) interface{} { key := ComponentKey{Type, which} var err error if component, ok := cc.components[key]; ok { return component } else if factory, ok := cc.factories[key]; ok { //IDEALLY locked on a per key basis. component, err = factory(cc, which) if err != nil { panic(err) } cc.components[key] = component return component } else if (cc.parent != null ){ return cc.parent.FetchComponent(Type, which) }else { panic(component) } } |
This allows caches to exist in a DAG structure. Object lifelines are sorted from shortest to longest: an object can point at another object either within the same cache, or of longer lifeline in the parent cache, chained up the ancestry.